How TorchServe could scale in a Kubernetes environment using KEDA
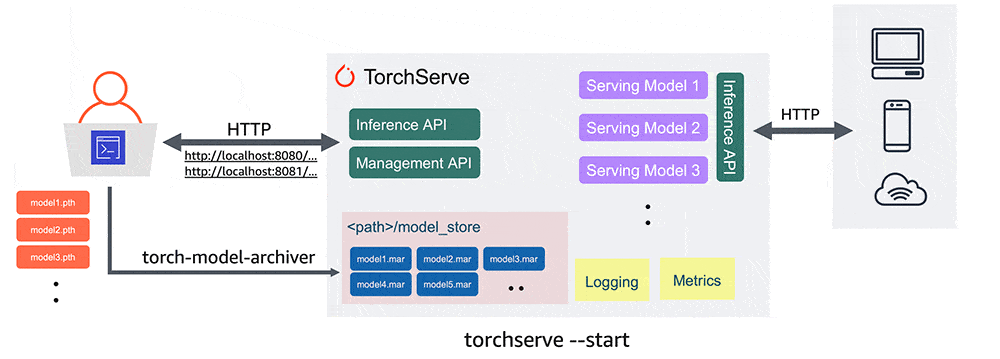
Some days ago I wrote the following blog post on how TorchServe can help to deliver AI models in production ready to serve inference requests.
Because I had some Azure credits left from my free tier (200$ for the first month),
an idea came in my mind: why not to try an NVIDIA A100 PCIe GPU (Standard_NC24ads_A100_v4) with 80GB of GPU trying to use it until its limit?
(from my rapid research this card should cost something like 7K Euros 😱😱😱)
So I did it and understood what it could be a really interesting idea to scale TorchServe in a Kubernetes environment.
Below you will find the tests and then an architecture which could be implemented on a Kubernetes production scenario to scale TorchServe workload based on custom metrics.
Tests
SamLowe/roberta-base-go_emotions
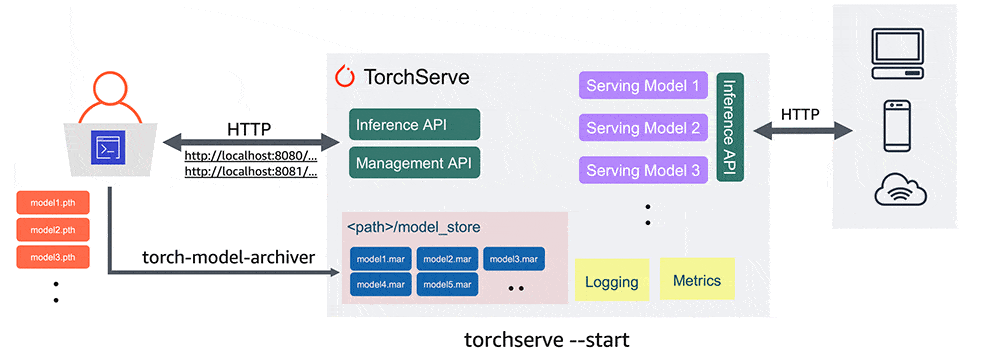
As I did in the above blog post, I runned TorchServe with the following setup:
- Text Classification Model
SamLowe/roberta-base-go_emotions (https://huggingface.co/SamLowe/roberta-base-go_emotions) - GPU enabled of course 😀
- 1 torchserve worker per each Pod
- 40 pods
- 30 parallel users
🚀🚀🚀🚀
In this way I reached a throughput of 418 requests per second with an avg response time of 68ms
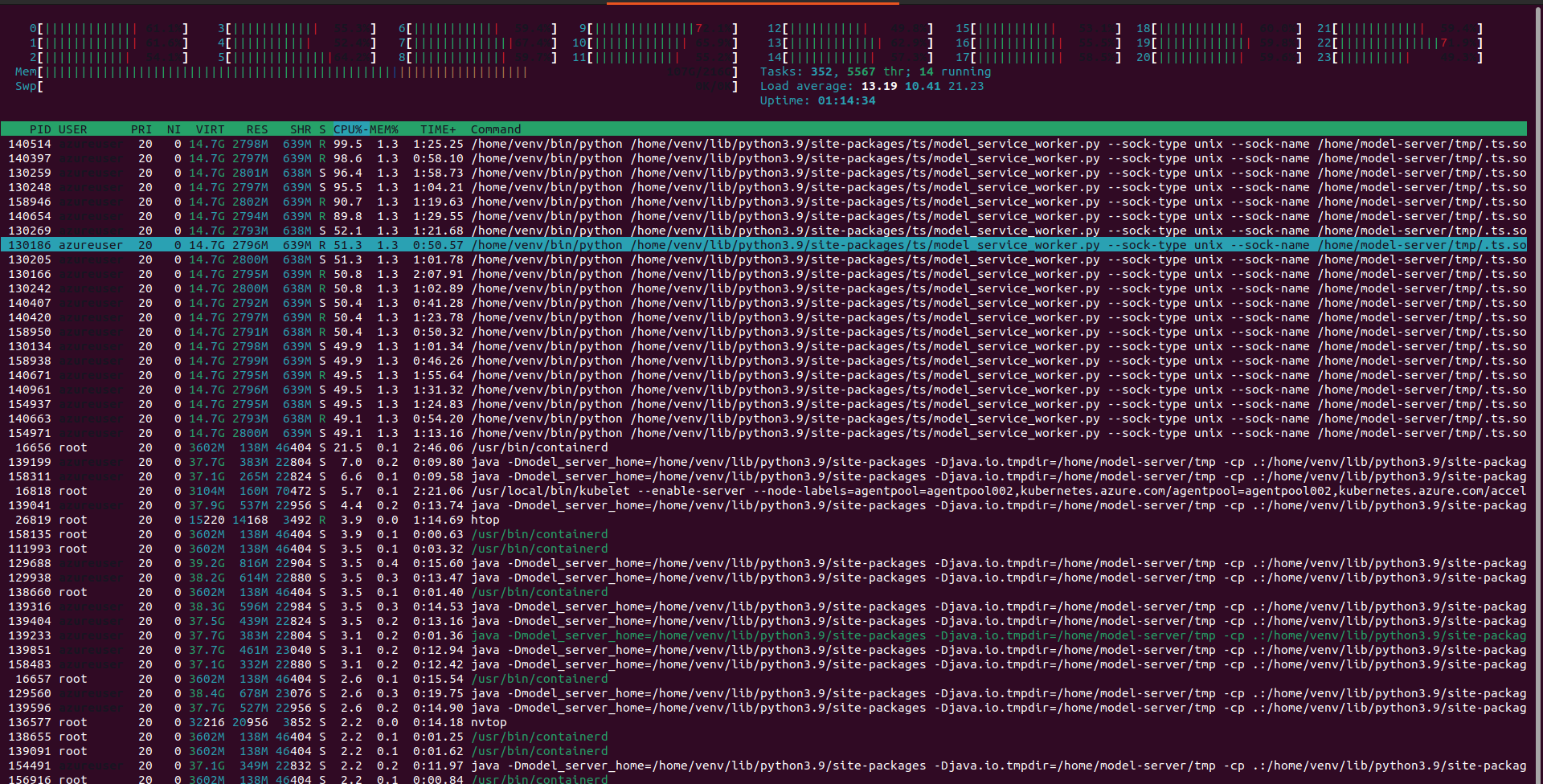
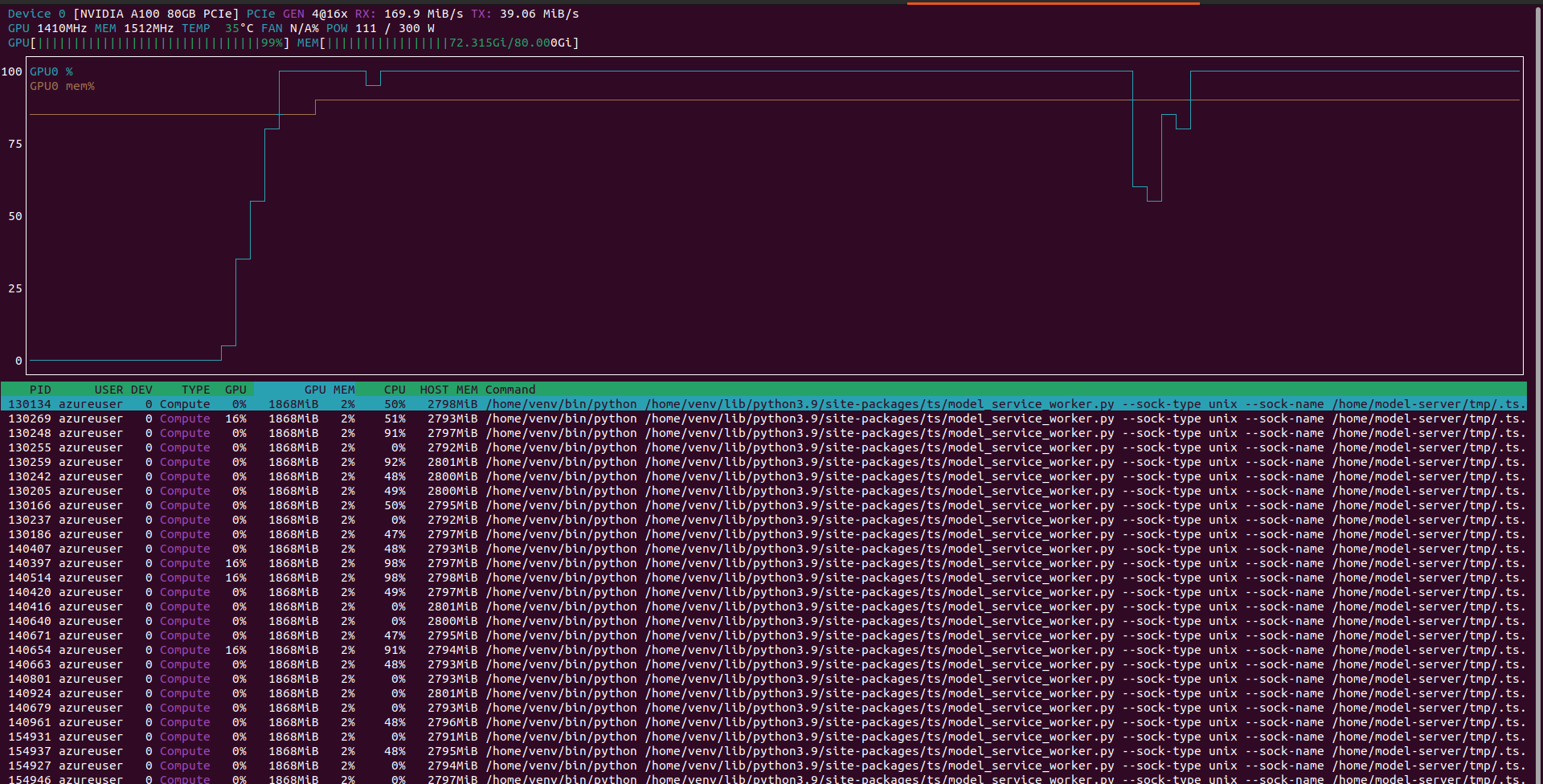
Full tests here https://github.com/texano00/TorchServe-Lab/blob/main/JMeter/results/aks/Standard_NC24ads_A100_v4/SamLowe_roberta-base-go_emotions/README.md
facebook/detr-resnet-50
- Object Detection Model
facebook/detr-resnet-50 (https://huggingface.co/facebook/detr-resnet-50) - GPU enabled of course 😀
- 5 torchServe worker per each Pod
- 1 pod
- 5 parallel users
In this way I reached a throughput of 16.9 requests per second with an avg response time of 280ms


Full test here https://github.com/texano00/TorchServe-Lab/blob/main/JMeter/results/aks/Standard_NC24ads_A100_v4/facebook_detr-resnet-50/README.md
Scale TorchServe
These tests allowed me to understand better one of the benefit of using TorchServe workers which is basically the optimization of CPU and Memory compared of scaling Kubernetes pods.
📉📉📉
In conclusion, increasing TorchServe workers instead of scaling Kubernetes pods produced a reduction of:
- -59% of CPU load avarage
- -20% of memory usage
GPU usage remained almost the same.
I supposed that it was possible thanks by TorchServe instances shared by multiple workers (see TorchServe internal architecture https://github.com/pytorch/serve/blob/master/docs/internals.md).
And looking to the scale process in a production environment, it could be interesting put together Kubernetes Horizontal Pod Autoscaler with TorchServe workers in order to meet the increase of inference requests.
So basically we can think a setup with a TorchServe minimum workers (based on needs) and than a pod autoscaling process based on the TorchServe custom metrics.
In this way we could take the advantages of TorchServe workers (as seen before) and Kubernetes pod autoscaling to ditribute our workload (high availability, fault tolerance, etc).
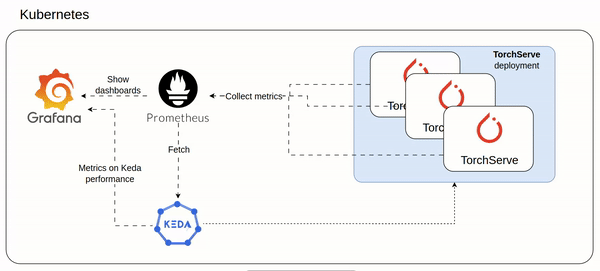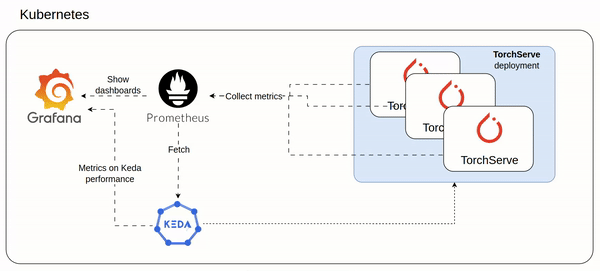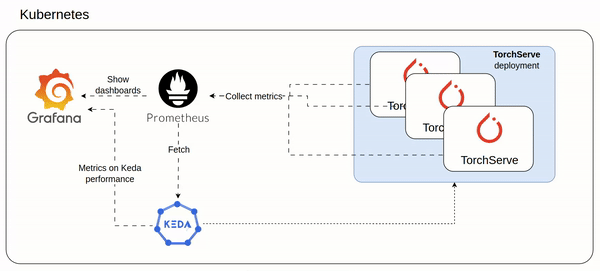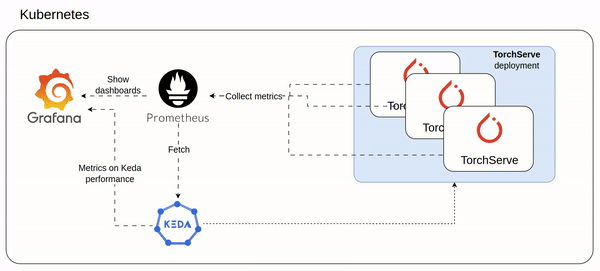
An idea of the architecture could be as follow involving mainly Keda and Prometheus:
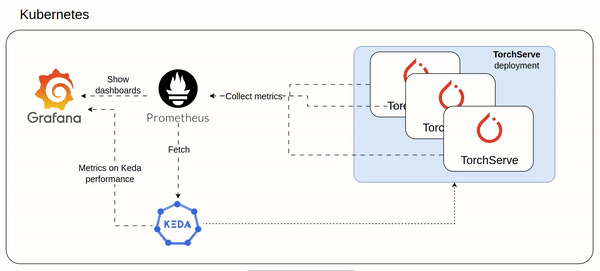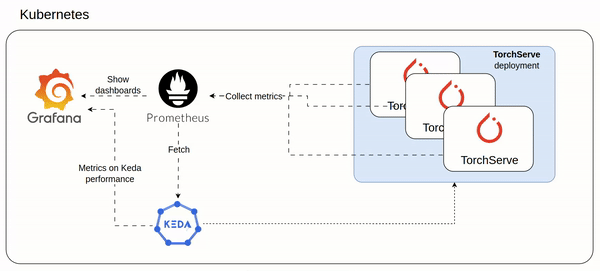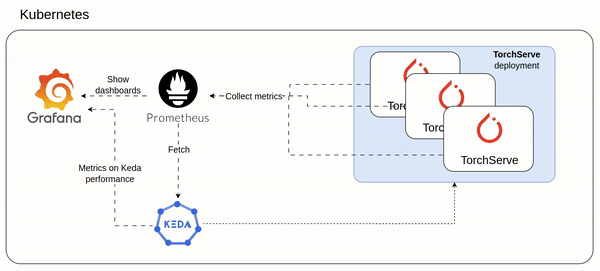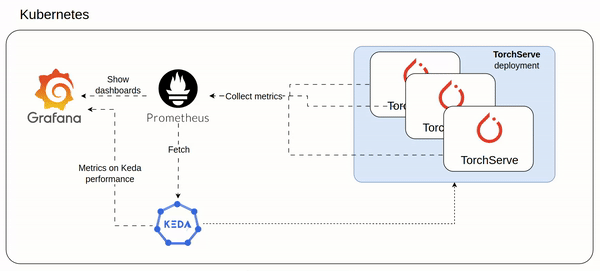
- Prometheus ingests custom metrics from all TorchServe pods (setup here https://www.yuribacciarini.com/serve-ai-models-using-torchserve/#5monitoring-stack)
- The TorchServe metrics are visible on a Grafana dashboard to monitor how TorchServe workload is performing
- Keda configured to scale TorchServe deployment based on prometheus custom metrics
- The same Keda exposes Prometheus like metrics which could be plotted on a Grafana dashboard to monitor how Keda is working
Important note: in order to allow the above process to work properly, you have to configure memory requests/limits of TorchServe deployment.
To do so, on NVIDIA cards, you have to install the NVIDIA device plugin (https://github.com/NVIDIA/k8s-device-plugin) in your cluster Kubernetes.
NVIDIA device plugin implements the official Kubernetes device plugin framework described here https://kubernetes.io/docs/concepts/extend-kubernetes/compute-storage-net/device-plugins/
Kubernetes provides a device plugin framework that you can use to advertise system hardware resources to the Kubelet.
In this way our pods are available to request a new type of resource named nvidia.com/gpu

Or, in a more realistic scenario (check NVIDIA supported cards) use Multi-Instance GPU (MIG) which allow to share in a secure way a phisical GPU and of course optimize its usage --> https://docs.nvidia.com/datacenter/tesla/mig-user-guide/index.html
Basically, from users side, it is a concept similar to Virtual CPU but in GPU.
Automatically scale TorchServe workers
Because TorchServe allows hot workers scale up/down through APIs without any restarts needed (https://pytorch.org/serve/management_api.html#scale-workers), it could be also interesting to automatially scale TorchServe workers based on the same custom metrics exposed by TorchServe itself.
curl -v -X PUT "http://<torch-serve-host>:8081/models/noop?min_worker=3"
< HTTP/1.1 202 Accepted
< content-type: application/json
< x-request-id: 42adc58e-6956-4198-ad07-db6c620c4c1e
< content-length: 47
< connection: keep-alive
<
{
"status": "Processing worker updates..."
}In this case, because every TorchServe worker needs a specific amount of memory almost easy to predict, we need also to automatically update the pods requests/limits memory using the following Kubernetes feature (alpha in v1.27) which allows to update it without restarting the pod.

This stuff is needed during both workers scale up and workers scale down to adjust the requested memory and also prevent memory waste (during TorchServe workes scale down).
In this way we ensure that the pods are always requesting the right amount of memory needed to run TorchServe with a dynamic number of internal workers.
It could be also interesting to use Vertical Pod Autoscaler instead of manual update pods requests/limits memory but I'm not sure of how much VPA is reactive and how much the TorchServe workers are fault tolerence related to not enough GPU memory.
Also in this case the above k8s feature of resizing Memory resources without restarting the pods is needed.
Finally, if Kubernetes is not able to continue running a pod after a TorchServe workers scale up,
it will put the pod in a waiting resources status so we will also be able to trigger Cluster Autoscaling mechanism to add new worker nodes and scale also on Kubernetes worker nodes side.
The main pitfall on Cluster Autoscaling is to avoid outages and serve the maximum inference requests at any time also during Cluster Autoscaling process.
An idea could be to anticipate the Kubernetes worker nodes scale UP before the TorchServe workers scaling in order to have a entire scale process as smooth as possible.

![[k8s] Automatically pull images from GitLab container registry without change the tag](/content/images/size/w750/2024/01/urunner-gitlab.png)